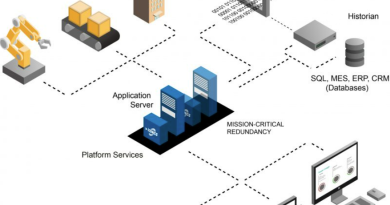
Aligning Historian with cloud
For many operators, data analysis and management still sometimes becomes a matter of Historian systems versus the cloud. The debate may initially seem logical and like cloud streamlines the process, but it typically leads to extortionately high operating costs. Instead, the best option may be to use the two together strategically to minimise cloud costs and get the most from your data.
Industrial processes generate thousands of terabytes of data every day, most of which can be calculated and analysed to offer insights on how to improve or optimise operations. More users that are experienced with data collection and analysis often eventually encounter the problem of system scalability: as more data is generated, the idea of using the cloud to store and process data might seem appealing.
It is this challenge that leads operators to mentally pit local data parsing and aggregation in Historian systems against storage and analysis in the cloud. The belief is that the large storage sizes boasted by cloud providers, alongside the appealing concept of off-site data processing without the computational requirements, is better suited for higher volumes of data produced by the evolving edge. The process could therefore be logically streamlined to connect edge devices and systems in such a way that they communicate data directly to the cloud, where it can be stored, processed into usable KPIs and accessed by staff.
However, this overlooks a crucial detail: cloud services usually have message-based charging structures.
Because directly connecting edge systems to the cloud means that raw data is pushed directly to the cloud without significant pre-processing, it means that hundreds of messages are sent every hour. It doesn’t appear to be a problem at first — until the finance department receives the monthly invoice.
Processing raw data in cloud systems is also relatively expensive. Most database technology for time series data in cloud is not optimised for read and write functionality. This means that overall performance suffers as a consequence, with seemingly the only way to alleviate these issues being to increase the capacity of the cloud service.
Both of these issues make the use of Historian systems apparent. This is not to say cloud is bad. It is good for scalability and freeing up local resources from data storage. But as with all things, it must be deployed and set up intelligently.
If Historian systems can aggregate edge data and perform simple calculations to refine that information, it reduces the volume of data sent to the cloud. It still provides engineers on the factory floor the option of viewing granular data, while letting managers and executives access the refined data via the cloud — reducing the cloud collection and processing burden.